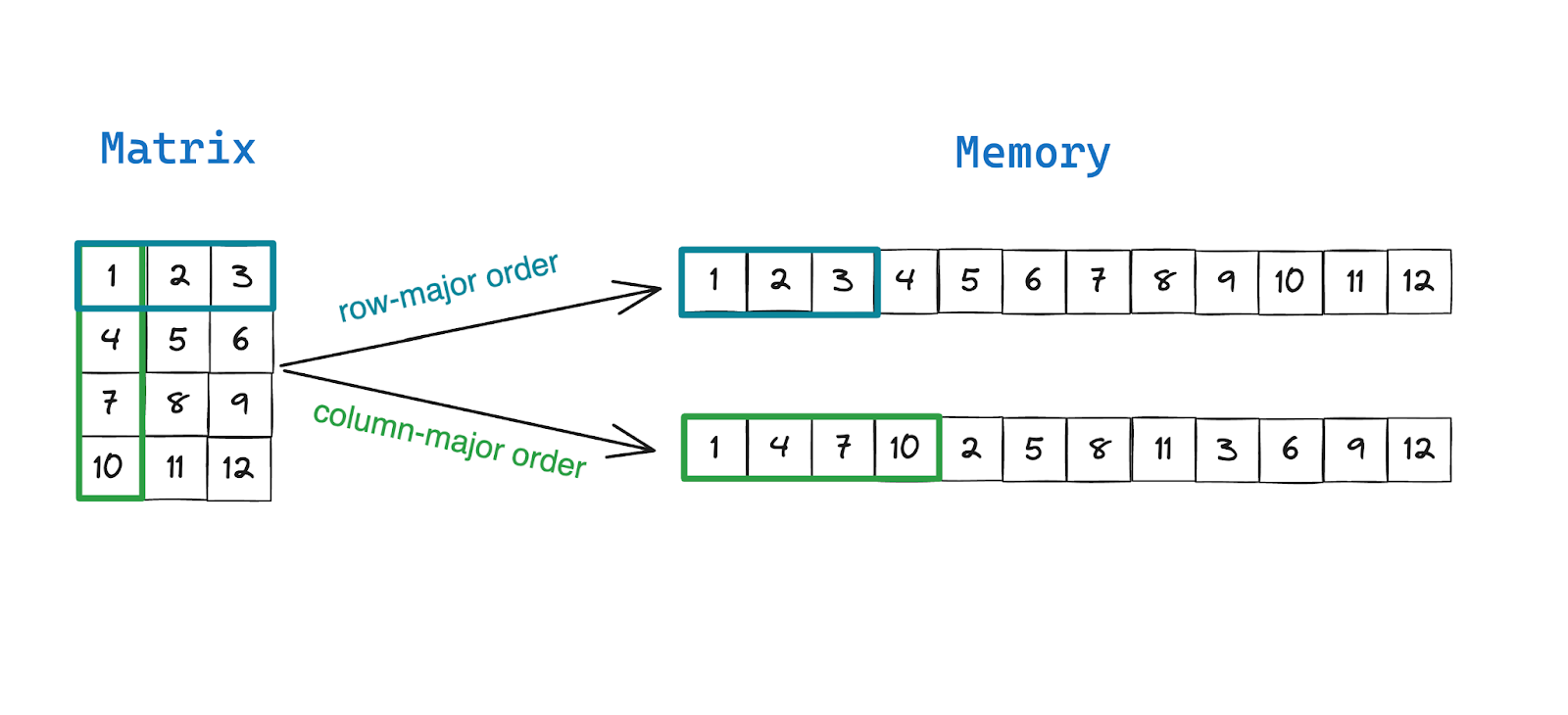
矩阵是定义线性变换的行向量和列向量的矩形集合。然而,矩阵并没有被实现为计算机内存中的矩形数字网格,我们将它们存储为连续内存中的大型元素数组。
在这篇博文中,我们将使用 Mojo🔥 仔细研究矩阵在内存中的存储方式,并回答以下问题:什么是行优先和列优先排序?是什么让他们与众不同?为什么某些语言和库更喜欢列优先顺序而其他语言和库更喜欢行优先顺序?内存排序对性能有何影响?
行主序与列主序
行优先和列优先是在内存中存储矩阵(和高阶张量)的不同方法。按照行优先顺序,行向量或行中的元素存储在连续的内存位置中。按照列优先顺序,列向量或列中的元素存储在连续的内存位置中。由于读取和写入存储在连续内存中的数据速度更快,因此需要频繁访问行中元素的算法在行主序矩阵上运行得更快,而需要频繁访问列中元素的算法在列主序矩阵上运行得更快。
MATLAB、Fortran、Julia 和 R 等编程语言默认以列优先顺序存储矩阵,因为它们通常用于处理表格数据集中的列向量。流行的 Python 库 Pandas 也使用列主内存布局来存储 DataFrame。另一方面,C、C++、Java 等通用语言和 NumPy 等 Python 库默认更喜欢行主内存布局。
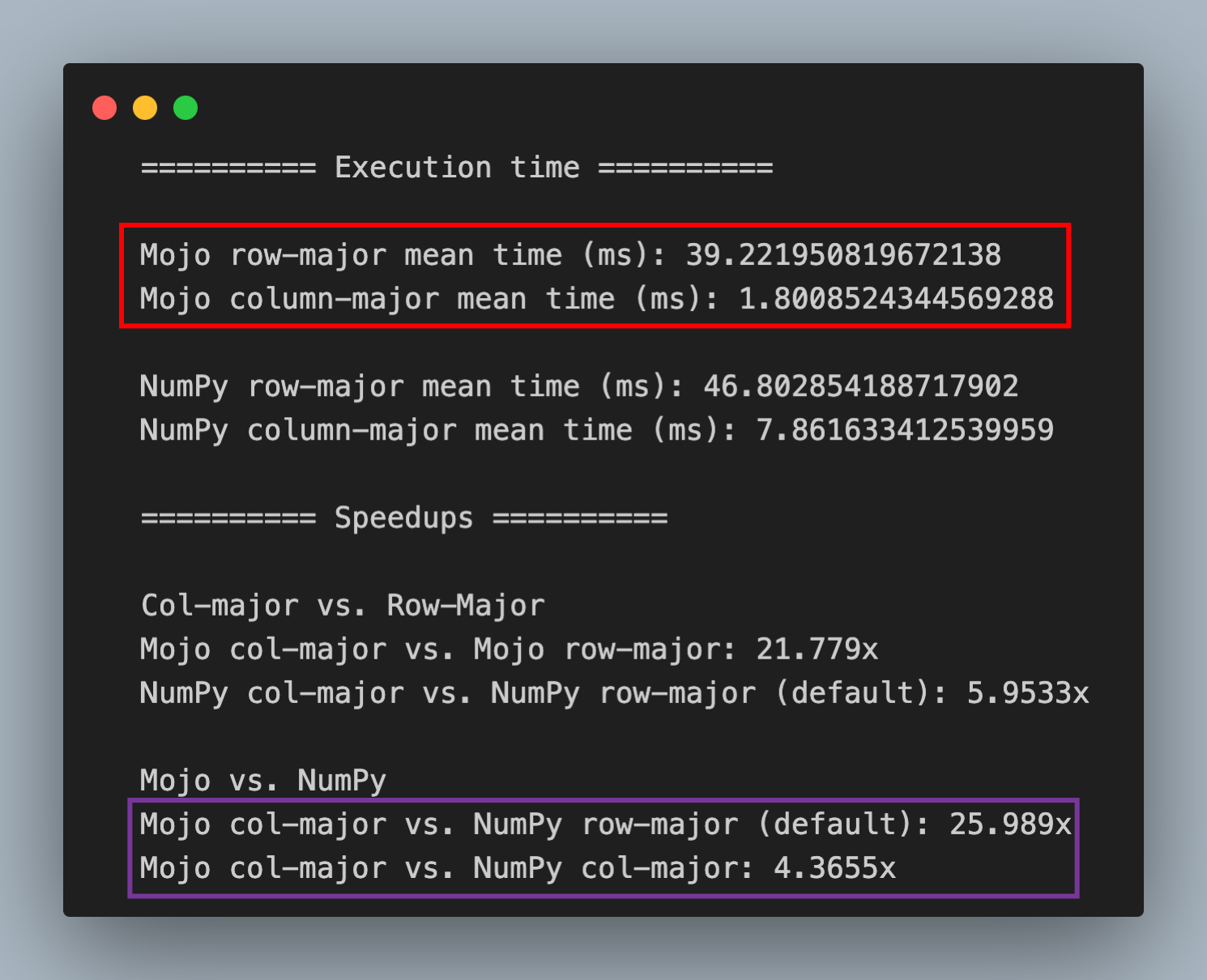
让我们举一个数据科学中常见操作的示例,该操作涉及对存储在数据库中的大型表格数据集中的较小列子集执行归约操作(总和、平均值、方差)。使用列主序矩阵对列进行约简操作的性能显着优于行主序矩阵,因为从连续内存中读取列值比跨步(跨内存跳跃)读取列值要快。在下面的红框中,您可以看到使用 Mojo 在我的 M2 MacBook Pro 上的性能差异。在紫色框中,您可以看到 Mojo 在 NumPy 的行主序和列主序矩阵方面也优于 NumPy。
在 Mojo 中实现行主序和列主序矩阵
为了更好地理解矩阵如何存储在内存中,以及它如何影响性能,让我们:
- 在 Mojo 中实现一个名为MojoMatrix的自定义矩阵数据结构,它允许您使用行优先或列优先顺序的数据实例化矩阵
- 检查行优先和列优先矩阵及其内存布局,以及它们之间的关系以及它们的转置关系
- 对行主矩阵和列主矩阵实现快速矢量化列缩减操作并比较它们的性能。
- 将它们的性能与 NumPy 的行主 ndarray(默认,C 顺序)和 NumPy 的列主 ndarray(F 顺序)进行比较
需要注意的是,矩阵元素在内存中的存储顺序不会影响矩阵的数学外观和行为。行/列主数纯粹是一个实现细节,但它确实会影响在矩阵上运行的算法的**性能。在GitHub 上随附的row_col_matrix.mojo 文件中,我实现了一个名为MojoMatrix的矩阵数据结构。MojoMatrix是一个准系统矩阵数据结构,它实现以下函数,我们将使用它来检查和了解数据布局及其对性能的影响。
- to_colmajor():一个函数,它接受具有行主要顺序的元素的 MojoMatrix 并返回具有列主要顺序的元素的 MojoMatrix
- Mean():以快速矢量化方式计算列均值的函数,在使用 NumPy 的列优先顺序时比 NumPy 的ndarray.mean()快 4 倍,比 NumPy 默认的行优先顺序快 25 倍。
- transpose():计算矩阵矢量化转置的函数,我们将用它来检查内存中的元素
- print()和print_linear():以矩阵格式打印矩阵的 print 函数,以及打印内存中布置的矩阵元素的 print_linear 函数
- from_numpy():一个方便的静态函数,它将 NumPy 数组复制到 MojoMatrix,以便我们可以测量性能并比较相同数据的性能
- to_numpy():一个便捷函数,可将 MojoMatrix 数据复制到 NumPy 数组,以验证 Mojo 和 NumPy 中执行的操作的准确性
在运行基准测试之前,让我们仔细看看 MojoMatrix 的使用。
from row_col_matrix import MojoMatrix
vals = List[Float64](1,2,3,4,5,6,7,8,9,10,11,12)
M = MojoMatrix(4,3,vals)
print(M)
print("Memory layout:")
M.print_linear()
在此示例中,我们创建一个简单的矩阵,类似于博客文章前面插图中显示的矩阵。
输出
[[1.0 2.0 3.0]
[4.0 5.0 6.0]
[7.0 8.0 9.0]
[10.0 11.0 12.0]]
Matrix: 4x3 | DType:float64 | Row Major
Memory layout:
[1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 9.0 10.0 11.0 12.0]
如果您仔细观察,您会发现矩阵输出显示“行主要” ,并且您可以从__print_linear()的输出中验证是否类似于前面插图中的行主要顺序布局。
现在让我们使用to_colmajor()将行主序矩阵转换为列主序矩阵
from row_col_matrix import MojoMatrix
vals = List[Float64](1,2,3,4,5,6,7,8,9,10,11,12)
M = MojoMatrix(4,3,vals)
mm_col_major = M.to_colmajor()
print(mm_col_major)
print("Memory layout:")
mm_col_major.print_linear()
输出
[[1.0 2.0 3.0]
[4.0 5.0 6.0]
[7.0 8.0 9.0]
[10.0 11.0 12.0]]
Matrix: 4x3 | DType:float64 | Column Major
Memory layout:
[1.0 4.0 7.0 10.0 2.0 5.0 8.0 11.0 3.0 6.0 9.0 12.0]
请注意, print(M)的输出与行主序矩阵的输出完全相同。这是因为矩阵如何存储在内存中是一个实现细节,不会也不应该影响您如何使用矩阵。
您还会注意到print_linear()的输出实际上是不同的。元素已重新排序,使得 4x3 矩阵的列在内存中彼此相邻。
矩阵转置与行主序和列主序有何关系?
转置运算交换矩阵的行和列,但不更改其内容。
如果你有一个矩阵中号米Xn然后你转置它,然后你得到中号nX米时间即行和列交换。

上图中,可以看到转置矩阵的元素顺序中号时间 以行优先顺序存储的矩阵元素的顺序与以列优先顺序存储的矩阵元素的顺序完全相同。主要区别在于转置矩阵中号nX米时间在数学上具有不同的属性,交换基本的行和列空间,同时存储相同的矩阵中号米Xn按列优先顺序只是一个实现细节。我们可以使用 MojoMatrix 及其transpose()和to_colmajor()函数来实现这一点并比较结果
from row_col_matrix import MojoMatrix
vals = List[Float64](1,2,3,4,5,6,7,8,9,10,11,12)
M = MojoMatrix(4,3,vals)
mm_col_major = M.to_colmajor()
print("Matrix in column-major order:")
print(mm_col_major)
print("Memory layout:")
mm_col_major.print_linear()
print("Transposed matrix:")
print(M.transpose())
print("Memory layout:")
M.transpose().print_linear()
输出
Matrix in column-major order:
[[1.0 2.0 3.0]
[4.0 5.0 6.0]
[7.0 8.0 9.0]
[10.0 11.0 12.0]]
Matrix: 4x3 | DType:float64 | Column Major
Memory layout:
[1.0 4.0 7.0 10.0 2.0 5.0 8.0 11.0 3.0 6.0 9.0 12.0]
Transposed matrix:
[[1.0 4.0 7.0 10.0]
[2.0 5.0 8.0 11.0]
[3.0 6.0 9.0 12.0]]
Matrix: 3x4 | DType:float64 | Row Major
Memory layout:
[1.0 4.0 7.0 10.0 2.0 5.0 8.0 11.0 3.0 6.0 9.0 12.0]
如果您检查transpose()和to_colmajor()函数实现,您会发现这两个函数之间的唯一区别是维度米Xn与nX米元素的实际重新排序隐藏在一个名为_transpose_order()的内部函数中,该函数由两者共享。
@always_inline
fn to_colmajor(self) raises -> MojoMatrix[dtype,False]:
assert_true(self.is_row_major == True, "Matrix must be in row-major format, to convert to column-major.")
return MojoMatrix[dtype, False](self.rows, self.cols, self._transpose_order())
@always_inline
fn transpose(self) -> MojoMatrix[dtype, is_row_major]:
return MojoMatrix[dtype, is_row_major](self.cols, self.rows, self._transpose_order())
fn _transpose_order(self) -> DTypePointer[dtype]:
var newPtr = DTypePointer[dtype].alloc(self.rows*self.cols)
alias simd_width: Int = self.simd_width
for idx_col in range(self.cols):
var tmpPtr = self._matPtr.offset(idx_col)
@parameter
fn convert[simd_width: Int](idx: Int) -> None:
newPtr.store[width=simd_width](idx+idx_col*self.rows, tmpPtr.simd_strided_load[width=simd_width](self.cols))
tmpPtr = tmpPtr.offset(simd_width*self.cols)
vectorize[convert, simd_width](self.rows)
return newPtr
行优先顺序与列优先顺序如何影响性能?
现在我们已经对行优先和列优先排序有了一些直觉,让我们讨论一下为什么它对性能很重要。在数据科学中,数据科学家通常从数据库或其他来源加载表格数据集,并将它们加载到 Pandas DataFrame或 NumPy 的ndarray中,并对数据集的列运行平均值、总和、中位数或拟合直方图等操作,以更好地理解数据分布。这些数据集具有某些属性:
- 它们是“又窄又高”的矩阵,即行数远远超过列数
- 并非每个列或特征或属性都是有用的,并且许多在计算中被丢弃或忽略
这意味着大多数数据访问模式将访问彼此不相邻的特定列的所有行。 Pandas 等库以及 MATLAB、Fortran 和 R 等专为必须处理此类数据和数据访问模式的统计和线性代数计算而设计的编程语言默认为列优先顺序。因此,让列中的元素按列主序排列在连续内存中是有意义的。
为了模拟这个问题,让我们定义一个问题陈述:在双精度值的10000x10000元素矩阵上,对 1000 个随机选择的列的子集执行mean()归约操作。这确保了大多数列不是彼此的邻居。
NumPy 基准测试:行主序与列主序矩阵
首先,我们对 NumPy 实现进行基准测试,以分析行优先与列优先排序的效果。您可以在 GitHub 上找到随附的文件python_mean_bench.py 。在此基准测试中,我们展示了两件事:
- 求 10000x10000 矩阵中所有列的平均值
- 求 1000 个随机选择列的子集的平均值
NumPy 允许您使用函数np.asfortranarray()从默认的 C 样式排序(行主顺序)切换到 Fortran F 样式排序(列主顺序),您可以看到巨大的性能差异。
Python
from timeit import timeit
import numpy as np
def row_major_mean(np_mat: np.ndarray, mean_idx=[]):
if len(mean_idx) == 0:
mean_idx = slice(None)
return 1000*timeit(lambda: np_mat[:,mean_idx].mean(axis=0), number=10) / 10
def col_major_mean(np_mat: np.ndarray, mean_idx=[]):
if len(mean_idx) == 0:
mean_idx = slice(None)
np_mat = np.asfortranarray(np_mat)
return 1000*timeit(lambda: np_mat[:,mean_idx].mean(axis=0), number=10) / 10
if __name__ == "__main__":
np_mat = np.random.rand(10000,10000)
print()
print("Mean of all columns, time (ms)")
print("------------------------------")
print("Row-major:", row_major_mean(np_mat))
print("Col-major:",col_major_mean(np_mat))
row_major_mean_vals = np_mat.mean(axis=0)
col_major_mean_vals = np.asfortranarray(np_mat).mean(axis=0)
np.testing.assert_almost_equal(row_major_mean_vals, col_major_mean_vals)
print("Accuracy comparision (2-Norm of difference):", np.linalg.norm(row_major_mean_vals - col_major_mean_vals))
print()
print("Mean of 1000 random columns, time (ms)")
print("--------------------------------------")
mean_idx = np.random.randint(0,10000,1000)
print("Row-major:", row_major_mean(np_mat,mean_idx))
print("Col-major:",col_major_mean(np_mat,mean_idx))
row_major_mean_vals = np_mat[:,mean_idx].mean(axis=0)
col_major_mean_vals = np.asfortranarray(np_mat[:,mean_idx]).mean(axis=0)
np.testing.assert_almost_equal(row_major_mean_vals, col_major_mean_vals)
print("Accuracy comparision (2-Norm of difference):", np.linalg.norm(row_major_mean_vals - col_major_mean_vals))
print()
输出
Mean of all columns, time (ms)
------------------------------
Row-major: 24.860700010322034
Col-major: 20.25612499564886
Accuracy comparision (2-Norm of difference): 1.4372499570202904e-13
Mean of 1000 random columns, time (ms)
--------------------------------------
Row-major: 47.35492919571698
Col-major: 7.3962084017694
Accuracy comparision (2-Norm of difference): 0.0
第一个结果是计算每列的平均值,您会发现行优先顺序和列优先顺序的性能很小。为什么性能上没有更大的差异?毕竟,访问行主序矩阵中的列需要跨步内存访问,这会比较慢。
NumPy 实现利用了行值在内存中仍然连续的事实,并且能够使用 SIMD 指令同时减少多个列。但是当随机选择列时,这种优化对我们没有帮助。这就是为什么您会在第二个结果中看到巨大的性能差异:1000 个随机列的平均值,时间 (ms),其中 NumPy 的列主序矩阵比 NumPy 的行主序矩阵快约 6 倍。
Mojo 基准测试:行主序与列主序矩阵
现在让我们使用 Mojo 中的 MojoMatrix 来解决此任务。我不会在这篇博文中讨论MojoMatrix的实现细节,您可以在 GitHub 上找到完整的实现。这是该结构的骨架:
struct MojoMatrix[dtype: DType = DType.float64, is_row_major: Bool=True]():
@always_inline
fn __init__(...):
...
@always_inline
fn __len__(self) -> Int:
...
fn _transpose_order(self) -> DTypePointer[dtype]:
...
@always_inline
fn to_colmajor(self) raises -> MojoMatrix[dtype,False]:
...
@always_inline
fn transpose(self) -> MojoMatrix[dtype, is_row_major]:
...
@always_inline
fn mean(self, owned cols_list:List[Int]) -> Self:
...
@staticmethod
fn from_numpy(np_array: PythonObject) raises -> Self:
...
fn to_numpy(self) raises -> PythonObject:
...
fn print_linear(self):
...
fn __str__(self) -> String:
...
在MojoMatrix的__Mean()函数中,我实现了一个快速的向量化归约运算,该运算适用于行主序矩阵和列主序矩阵。
@always_inline
fn mean(self, owned cols_list:List[Int]) -> Self:
var new_mat = Self(1,len(cols_list))
alias simd_width: Int = self.simd_width
var simd_sum = SIMD[dtype, simd_width](0)
var simd_multiple = align_down(self.rows, simd_width)
for idx_col in range(len(cols_list)):
simd_sum = simd_sum.splat(0)
if is_row_major:
var tmpPtr = self._matPtr.offset(cols_list[idx_col])
for idx_row in range(0, simd_multiple, simd_width):
simd_sum+=tmpPtr.simd_strided_load[width=simd_width](self.cols)
tmpPtr += simd_width*self.cols
for idx_row in range(simd_multiple, self.rows):
simd_sum[0] += tmpPtr.simd_strided_load[width=1](self.cols)
tmpPtr += self.cols
new_mat._matPtr[idx_col] = simd_sum.reduce_add()
else:
for idx_row in range(0, simd_multiple, simd_width):
simd_sum+=self._matPtr.load[width=simd_width](self.rows*cols_list[idx_col]+idx_row)
for idx_row in range(simd_multiple, self.rows):
simd_sum[0] += self._matPtr.load[width=1](self.rows*cols_list[idx_col]+idx_row)
new_mat._matPtr[idx_col] = simd_sum.reduce_add()
new_mat._matPtr[idx_col] /= self.rows
return new_mat
在上面的代码中,我对行优先和列优先顺序矩阵有两种不同的方法。
行主序算法:在行主序中,列向量值不存储在连续的内存中,而是按步长 = 列数分隔。我们仍然可以通过使用函数simd_strided_load[simd_width](offset=number_of_column)加载系统的 SIMD 宽度值来执行矢量化缩减。如果矩阵中的行数不是系统 SIMD 宽度的倍数,则溢出值会在第二个循环中以非矢量化方式减少idx_row in range(simd_multiple, self.rows) 。
列主序算法:在列主序中,列向量存储在连续的内存位置中,因此使用 SIMD 向量化加载值和减少值要快得多。与之前一样,如果矩阵中的行数不是系统 SIMD 宽度的倍数,则溢出值会在第二个循环中以非矢量化方式减少idx_row in range(simd_multiple, self.rows) 。
在这两种情况下,我们都会验证结果与 NumPy 中的结果在非常小的容差值内匹配。以下是🥁鼓声🥁结果:
from row_col_matrix import MojoMatrix
import benchmark
from random import random_si64
from benchmark import Unit, keep
from python import Python
from time import sleep
from testing import assert_almost_equal
from algorithm import vectorize
fn mojo_to_py_list(list: List[Int]) raises -> PythonObject:
var py_list = PythonObject([])
for idx in list:
py_list.append(idx[])
return py_list
fn print_numpy_compare_norm(np_mat: PythonObject, mat: MojoMatrix, mean_idx: List[Int]) raises -> Float64:
var np = Python.import_module("numpy")
var np_mean: PythonObject
var mat_mean: PythonObject
if len(mean_idx)==0:
np_mean = np_mat.mean(axis=0)
mat_mean = mat.mean(mean_idx).to_numpy()
else:
np_mean = np_mat.take(mojo_to_py_list(mean_idx),axis=1).mean(axis=0)
mat_mean = mat.mean(mean_idx).to_numpy()
return np.linalg.norm(np_mean - mat_mean).to_float64()
fn bench_row_major(np_mat: PythonObject, mean_idx: List[Int]) raises -> Float64:
var mat = MojoMatrix.from_numpy(np_mat)
@parameter
fn benchmark_fn():
var m = mat.mean(mean_idx)
keep(m._matPtr)
var report_row_major = benchmark.run[benchmark_fn]()
print("Row-major accuracy check vs. NumPy. (2-Norm of difference):",str(print_numpy_compare_norm(np_mat, mat, mean_idx)))
return report_row_major.mean(Unit.ms)
fn bench_col_major(np_mat: PythonObject, mean_idx: List[Int]) raises -> Float64:
var mat = MojoMatrix.from_numpy(np_mat).to_colmajor()
@parameter
fn benchmark_fn():
var m = mat.mean(mean_idx)
keep(m._matPtr)
var report_col_major = benchmark.run[benchmark_fn]()
print("Column-major accuracy check vs. NumPy. (2-Norm of difference):",str(print_numpy_compare_norm(np_mat, mat, mean_idx)))
return report_col_major.mean(Unit.ms)
fn bench_numpy_row_major(np_mat: PythonObject, mean_idx: PythonObject) raises -> Float64:
Python.add_to_path(".")
var numpy_mean = Python.import_module("python_mean_bench")
return numpy_mean.row_major_mean(np_mat, mean_idx).to_float64()
fn bench_numpy_col_major(np_mat: PythonObject, mean_idx: PythonObject) raises -> Float64:
Python.add_to_path(".")
var numpy_mean = Python.import_module("python_mean_bench")
return numpy_mean.col_major_mean(np_mat, mean_idx).to_float64()
np = Python.import_module("numpy")
np_mat = np.random.rand(10000,10000)
mean_idx = List[Int]()
for i in range(1000):
mean_idx.append(int(random_si64(0,10000)))
row_major_mean_time = bench_row_major(np_mat, mean_idx)
col_major_mean_time = bench_col_major(np_mat, mean_idx)
numpy_row_major_mean_time = bench_numpy_row_major(np_mat, mojo_to_py_list(mean_idx))
numpy_col_major_mean_time = bench_numpy_col_major(np_mat, mojo_to_py_list(mean_idx))
print()
print("========== Execution time ==========")
print()
print("Mojo row-major mean time (ms):",row_major_mean_time)
print("Mojo column-major mean time (ms):",col_major_mean_time)
print()
print("NumPy row-major mean time (ms):",numpy_row_major_mean_time)
print("NumPy column-major mean time (ms):",numpy_col_major_mean_time)
print()
print("========== Speedups ==========")
print()
print("Col-major vs. Row-Major")
print("Mojo col-major vs. Mojo row-major:",str(row_major_mean_time/col_major_mean_time)[:6],end='x\n')
print("NumPy col-major vs. NumPy row-major (default):",str(numpy_row_major_mean_time/numpy_col_major_mean_time)[:6],end='x\n')
print()
print("Mojo vs. NumPy")
print("Mojo col-major vs. NumPy row-major (default):",str(numpy_row_major_mean_time/col_major_mean_time)[:6],end='x\n')
print("Mojo col-major vs. NumPy col-major:",str(numpy_col_major_mean_time/col_major_mean_time)[:6],end='x\n')
输出
Row-major accuracy check vs. NumPy. (2-Norm of difference): 4.6304020458622057e-14
Column-major accuracy check vs. NumPy. (2-Norm of difference): 4.6304020458622057e-14
========== Execution time ==========
Mojo row-major mean time (ms): 39.216590163934427
Mojo column-major mean time (ms): 1.7989985130111523
NumPy row-major mean time (ms): 47.462849994190037
NumPy column-major mean time (ms): 8.4675250109285116
========== Speedups ==========
Col-major vs. Row-Major
Mojo col-major vs. Mojo row-major: 21.799x
NumPy col-major vs. NumPy row-major (default): 5.6052x
Mojo vs. NumPy
Mojo col-major vs. NumPy row-major (default): 26.382x
Mojo col-major vs. NumPy col-major: 4.7067x
在 Mojo 中,行优先顺序和列优先顺序之间的性能差异非常显着。对于此问题,列优先顺序比行优先顺序提供 21 倍的加速。整个实现是 25 行 Mojo 代码,它比 NumPy 的默认行主序实现快 26 倍,比 NumPy 的列主序实现快 4 倍,这两者都是我们在上一节中看到的。所有性能都是在配备 M2 处理器的 MacBook Pro 上测量的。
结论
我希望您喜欢这本关于行主序和列主序矩阵的入门知识,以及为什么它对性能很重要。如果您想继续探索,这是您的作业:
- 尝试使用我共享的实现作为起点来实现矩阵向量乘积M@v ,并对行主序__M和列主序M之间的性能进行基准测试。 (提示:行主序 M 应该更快,但为什么呢?)
- 尝试对行主序和列主序矩阵上的列进行缩放变换
- 对行主阶和列主阶矩阵实现矩阵分解运算。
使用两者有很多好处,并且可以选择在两者之间切换是件好事。 Mojo 可以非常方便地表达科学思想,而无需牺牲性能。