开源地址:https://github.com/dorjeduck/kamo
此存储库通过将 KAN Python 实现从ML 轻松移植到 Mojo 来探索 KAN。这个非常易读的 Python 实现提供了一个灵活的基础,可以将其实例化为 KAN 或经典 MLP,从而允许进行各种比较和实验。主要重点是理解核心概念,而不是优化性能或实现 KAN 的所有方面。
赋能边缘
KAN 的根本创新在于其可学习的边缘激活函数。论文《KAN:Kolmogorov-Arnold Networks》建议使用 B 样条函数和 SiLU 函数的线性组合。后续研究还建议使用切比雪夫多项式等。这些函数的一个关键特征是它们的导数定义明确且易于计算,这对于梯度下降优化至关重要。
B 样条和 SILU
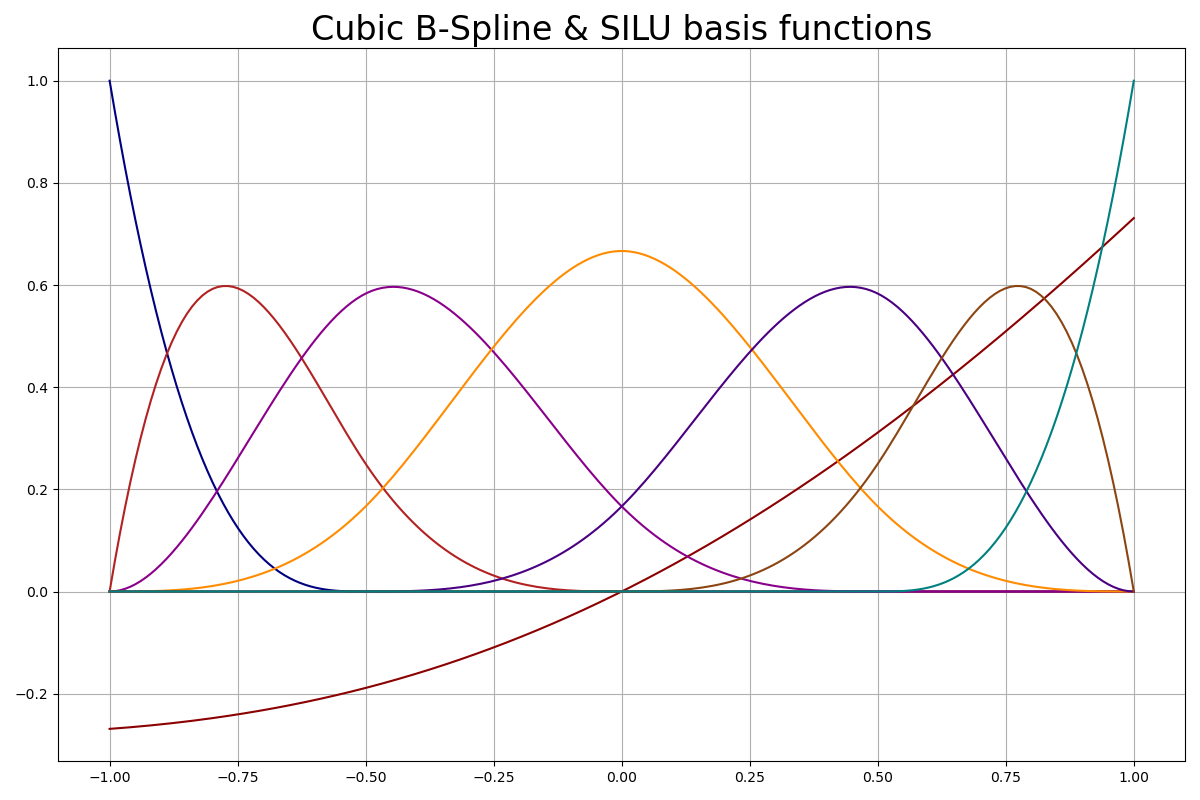
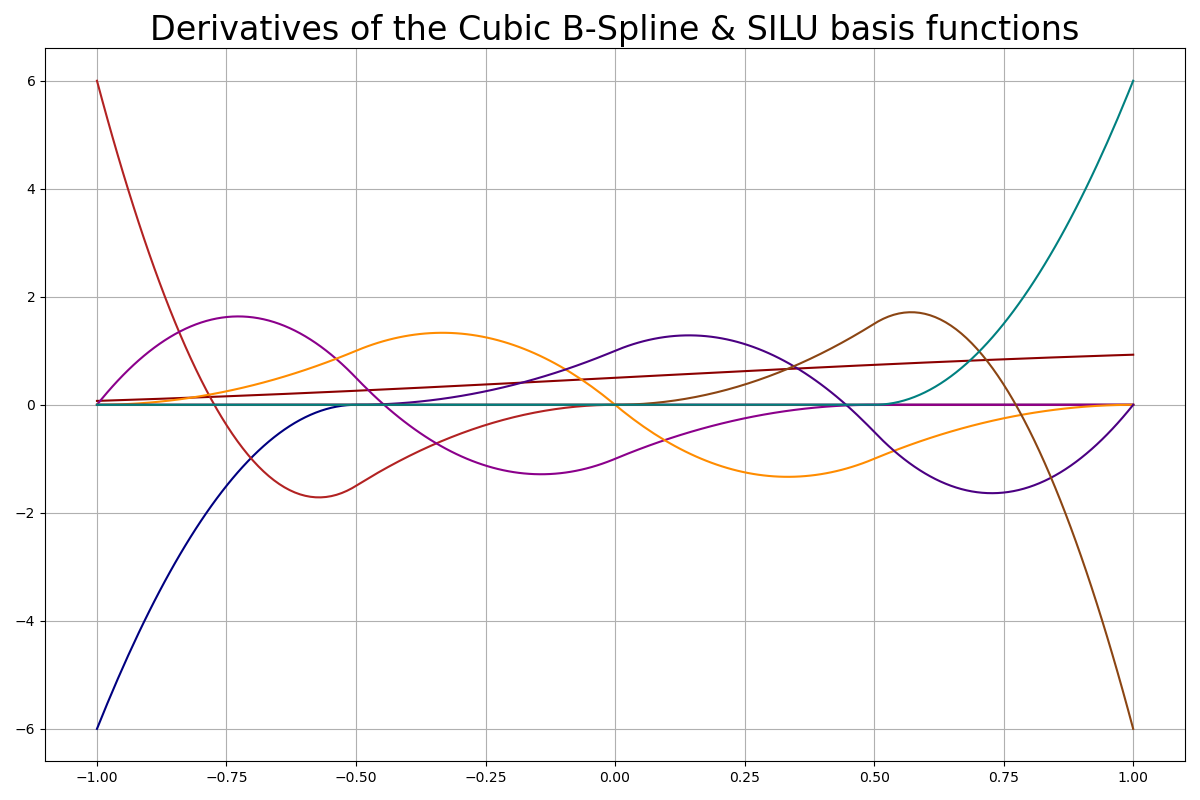
用法
先决条件:确保您已安装Mojo 24.4。
ML without tears实现提供了一些基本的使用示例供您入门。我们将前两个示例移植到了Mojo。
一维回归问题
请参阅train_1d.mojo了解简单的 1D 回归问题。此示例比较了经典 MLP 与三个 KAN 网络的性能:一个使用基于 B 样条线的边缘,另一个使用基于切比雪夫多项式的边缘,第三个使用基于高斯 RBF 的边缘。

表现:

二维回归问题
train_2d.mojo实现了 2D 回归问题。我们再次比较了经典 MLP 与三个 KAN 网络的性能:基于 B 样条、基于切比雪夫多项式和基于高斯 RBF 的边缘

表现:

正在学习
目前,该项目仅用于我们自己的教育目的,目前没有计划使其适用于实际应用。与原始 Python 代码类似,此 KAN 实现优先考虑网络透明度而不是速度。如果您正在寻找具有竞争性性能特征的 Mojo 深度学习框架,请查看Basalt。
评论
- 当前的实现仅涵盖了基本的 KAN 概念。论文《KAN:Kolmogorov-Arnold 网络》提出了各种增强 KAN 的方法,例如稀疏化和网格扩展,并激发了广泛的后续研究。我们的实现还有很大的改进空间。
- 为简单起见,我们使用
tanh将边缘输入归一化为样条网格的范围。该技术被其他性能优化的 KAN 实现广泛使用(例如,参见FasterKAN)。
- Mojo 正在快速发展,但仍然很年轻,在某些方面还很有限,例如对动态多态性的全面支持。我们代码中的一些样板代码就是由于这些限制造成的。随着 Mojo 的不断成熟,我们期待改进我们的实现。
资源
- 与上述论文相关的 GitHub 存储库可以在这里找到:pykan。
- 很棒的 KAN精选与 Kolmogorov-Arnold 网络 (KAN) 相关的很棒的库、项目、教程、论文和其他资源的列表。
更新日志